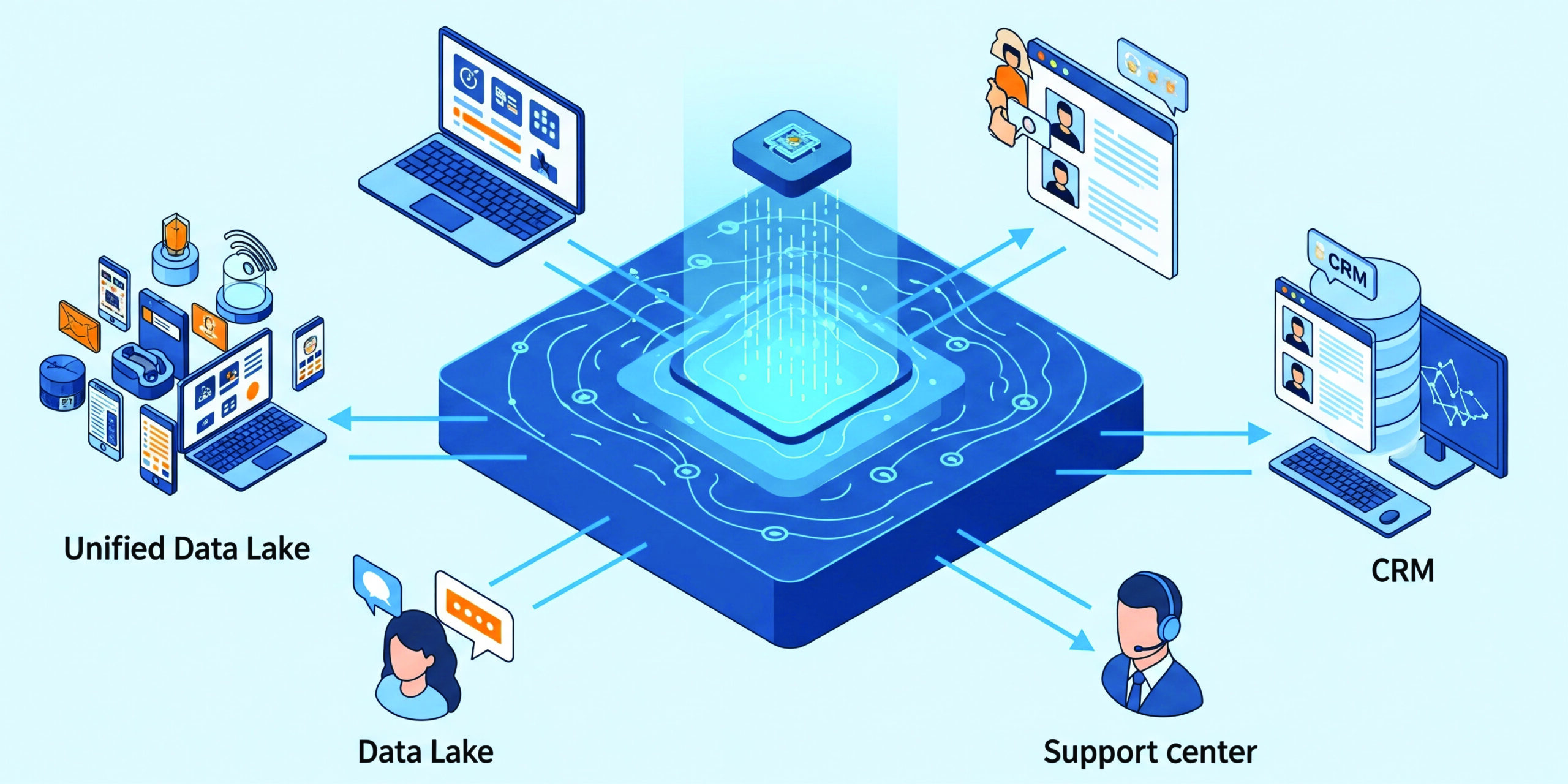
In today’s product-driven businesses—especially in sectors like Consumer Electronics, HVAC, and IoT—data is being generated at an unprecedented rate across device fleets, customer support channels, and CRM systems. Yet, for many engineering and data leaders, the challenge isn’t the availability of data—it’s the fragmentation of it.
This fragmentation is more than a technical hurdle; it’s a strategic bottleneck. AI teams can’t train models effectively. Business teams operate in silos. Product leaders miss out on insight-rich correlations—like whether a firmware update correlates with increased support calls, or if a customer churned after repeated ticket friction.
We encountered this very challenge—and solved it by designing a unified data lake that became a launchpad for AI-powered decision-making. Here’s how we did it.
I. Why AI Efforts Stall Without Unified Data
AI’s promise in modern enterprises is clear: smarter predictions, proactive support, and personalized customer experiences. But these outcomes rely on one foundational truth—clean, complete, and connected data.
Unfortunately, most companies still store their data in silos:
- Device telemetry sits isolated in cloud buckets or time-series databases.
- CRM data lives in platforms like Salesforce, holding valuable insights into segments, regions, and usage patterns.
- Support data—complaints, resolutions, NPS feedback—is tucked away in tools like Zendesk.
With no shared identity model and no integration, teams struggle to answer even basic questions:
- Is this support ticket linked to a recent firmware update?
- Do customers with high churn risk exhibit specific device usage patterns?
- Are certain product lines driving higher support costs?
Without a unified data backbone, these questions remain unanswered—and AI initiatives stall before they start.
II. The Problem: 3 Systems, 3 Stories, No Unity
When we first stepped into the engagement, the customer had three distinct systems managing different parts of the device lifecycle:
- Device Cloud: IoT telemetry streamed into AWS S3 and time-series DBs like Amazon Timestream. However, device logs were voluminous, semi-structured, and detached from customer context.
- CRM: Salesforce housed customer profiles, subscription details, onboarding stages, and communication logs. But no technical linkage to actual device usage existed.
- Support Platform: Zendesk captured tickets, sentiment ratings, and feedback loops. Again, isolated—no direct mapping to device logs or customer journey history.
Key challenges:
- Lack of a common device-customer identifier across systems
- No ability to correlate device behavior with ticket sentiment or CRM segments
- Manual, ad-hoc analytics processes involving exports, joins, and Excel wrangling
- Blocked AI teams, who couldn’t reliably access joined, labeled training datasets
The client didn’t need just another dashboard. They needed a robust data architecture that would serve analytics today—and AI tomorrow.
III. Our Unified Data Lake Approach
We built a cloud-native lakehouse architecture on AWS to ingest, standardize, and enrich data from all three sources—device, CRM, and support.
✅ Core Foundation:
- Storage: Amazon S3 as the core lake with structured folder-based zoning
- Cataloging & Governance: AWS Glue and Lake Formation for schema discovery, lineage, and security policies
- Ingestion Pipelines:
- Device telemetry: Real-time ingestion via Kinesis Firehose into the raw zone
- CRM data: Scheduled API pulls from Salesforce via AWS Lambda and Step Functions
- Support tickets: Real-time webhook ingestion from Zendesk
🧱 Four-Zone Lakehouse Structure:
- Raw: Unfiltered, source-native dumps
- Cleansed: Schema-aligned, validated datasets (CSV/Parquet)
- Analytics: Optimized for query with partitioning, joins, and denormalization
- ML-Ready: Feature-engineered datasets tailored for model training
This zoning enabled multiple consumer personas—BI teams, product managers, data scientists—to safely and efficiently work off the same source of truth.
IV. Stitching the Data: Creating a Unified Entity Graph
Ingesting data was just the first step. The real unlock came from stitching disparate entities into a unified view.
🔗 Identity Mapping:
- Device serial numbers were matched with CRM customer IDs using onboarding registration logs.
- Support tickets were linked to device serials and timestamps by parsing custom Zendesk fields.
We created a graph of relationships:
- One customer → multiple devices
- One device → telemetry timeline + support history
- One CRM segment → mapped to device behavior clusters
This graph-powered model enabled:
- End-to-end lineage from raw ingestion to model input
- 360° behavioral timelines at the device or customer level
- The foundation for temporal ML models and anomaly detection
V. AI Use Cases Powered by the Lake
With fused, structured data in place, we kickstarted multiple ML workflows using Amazon SageMaker:
🤖 Reusable AI Pipelines:
- Predictive Maintenance: Modeled time-series signals to forecast failures 10–15 days in advance
- Churn Prediction: Combined low NPS + ticket volume + usage drops to identify churn-prone users
- Sentiment Modeling: Used CRM notes and support feedback to build a sentiment scoring system per customer
All models were trained on curated features from the ML-ready zone and orchestrated using AWS Step Functions. Results were exposed via:
- Internal analytics dashboards (QuickSight)
- CRM pop-ups for support agents
- Customer portal insights for proactive outreach
VI. Business Enablement Outcomes
Within just 8 weeks of unified data lake deployment, the results were tangible:
| Impact Area | Before | After |
| Time to Insight | ~3 days | Under 4 hours |
| ML Models in Production | 0 | 4 |
| Support Call Volume | Baseline | ↓ 22% via proactive resolution |
| Customer Satisfaction | Fragmented tracking | Unified view + alerts |
More importantly, business users—from engineering leads to CX heads—could trust the insights they were seeing. No more wondering if data was stale, mismatched, or incomplete.
VII. Governance, Access, and Cost Optimization
Enterprise-grade data requires enterprise-grade controls.
We implemented:
- Row-level and column-level access policies via Lake Formation
- IAM-based role segregation for ML teams, BI users, support teams
- Storage class transitions (e.g., S3 Glacier) for aging telemetry
- Athena usage monitoring and query cost alerts to avoid runaway queries
This balance of granular access and cost optimization ensured the platform scaled without spiraling overhead.
VIII. Scalable Foundation for Future AI Workloads
What we built wasn’t just a tactical fix. It was a strategic enabler for long-term AI innovation.
🔮 Expandability Built-In:
- Ready to ingest mobile app usage metrics, session recordings, and firmware deployment logs
- Architected to support GenAI use cases:
- LLM-based ticket summarization
- AI-powered customer support chatbots combining structured and unstructured signals
And because we used Lake Formation cross-account access, this lake could now serve the entire enterprise—R&D, support, marketing, and even partners.
- Key Takeaways for Data Leaders
- Unifying device, CRM, and support data is not a backend chore—it’s a business transformation layer.
- AI success is a function of data architecture: ingestion pipelines, identity mapping, governance, and clean labeling.
- A unified data lake doesn’t just feed ML—it becomes the system of intelligence that powers decision-making across product, support, and customer success.
For any OEMs navigating fragmented data chaos, this approach turns technical debt into strategic advantage—unlocking the real value of AI.